vLLM-Omni
vLLM-Omni là framework để tự host và phục vụ model text, ảnh, video và audio trong cùng một hạ tầng, hợp với team muốn gom nhiều luồng inference về một chỗ thay vì dựng rời từng server.
https://github.com/vllm-project/vllm-omni ↗⭐ 5.287 sao 🍴 1.173 fork ~289 ngày tuổi, ~18.3 sao/ngày
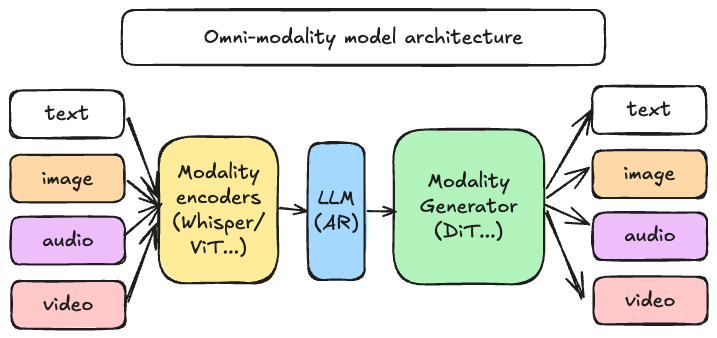
vLLM-Omni dùng để làm gì?
- ✓ Dồn model chat, tạo ảnh, TTS và video vào một lớp API chung để app nội bộ gọi dễ hơn.
- ✓ Thử nhiều model open-weight cho lab sáng tạo mà không phải dựng riêng mỗi model một stack serve khác nhau.
- ✓ Mở API tương thích OpenAI cho agent hoặc workflow nội bộ để đổi backend bớt đau hơn.
- ✓ Scale hạ tầng inference cho team đang build studio AI hoặc sản phẩm multimodal có traffic thật.
vLLM-Omni có gì nổi bật?
- •Mở rộng vLLM từ text generation sang text, image, video và audio serving trong cùng framework.
- •Hỗ trợ cả mô hình autoregressive lẫn diffusion và các pipeline đầu ra không đồng nhất.
- •Có OpenAI-compatible API server, streaming outputs và recipe triển khai tương đối rõ cho team infra.
- •README cho thấy dự án đã có stable release, paper và cộng đồng thảo luận riêng, nên không còn là demo nghiên cứu đơn lẻ.
vLLM-Omni thay được gì, tiết kiệm gì?
Khâu dựng riêng từng server inference cho từng loại model và tự ghép lớp API ở phía trên.
Tiết kiệm: Có thể giảm công ghép nhiều stack serve khác nhau khi team đã có GPU và người vận hành. Lợi ích lớn nhất là hợp nhất backend, không phải setup cực nhanh cho người mới.
Có thể thay: Một phần stack tự ghép giữa vLLM, server TTS riêng, server diffusion riêng và lớp API tùy biến
vLLM-Omni hợp với ai ở Việt Nam?
Một số team AI builder ở Việt Nam đang phải ghép vLLM, server TTS, diffusion stack và API layer theo kiểu mỗi thứ một nơi. vLLM-Omni đáng xem khi nhu cầu chuyển từ thử nghiệm một model sang vận hành cả cụm multimodal.
Vì sao đáng chú ý: Nhu cầu self-host model, chạy API tương thích OpenAI và tối ưu GPU đang tăng ở cộng đồng AI builder Việt. Riêng lớp phục vụ đa modality kiểu vLLM-Omni vẫn khá niche và chưa thấy nhiều nội dung tiếng Việt giải thích dễ hiểu.
⚠ Cần lưu ý gì trước khi dùng vLLM-Omni?
vLLM-Omni đòi hỏi Linux, GPU, hiểu model serving và vận hành backend. Nếu team chưa quen hạ tầng hoặc chỉ cần chạy một model đơn lẻ, chi phí học và vận hành sẽ cao hơn lợi ích.
Công cụ liên quan
-
Dream Server
Dream Server là bộ cài local AI all-in-one giúp bạn biến PC, Mac hoặc máy Linux thành stack AI riêng với chat, model serving, voice, workflow, RAG và image generation mà không phải tự nối hàng chục dịch vụ từ đầu.
-
Pixelle-Video
Pixelle-Video là công cụ tạo video ngắn tự động: bạn nhập một chủ đề, hệ thống tự viết kịch bản, tạo hình/clip AI, đọc voice, thêm nhạc nền rồi ghép thành video hoàn chỉnh.
-
Toonflow
Toonflow là app desktop AI giúp biến truyện, tiểu thuyết hoặc kịch bản thành phim hoạt hình ngắn bằng các bước viết lại, chia cảnh, tạo nhân vật và sinh video.
-
Guizang PPT Skill
Guizang PPT Skill giúp Claude Code/Codex dựng nhanh một deck HTML nhìn chỉn chu, theo phong cách editorial magazine hoặc Swiss design, kèm gợi ý ảnh, cover social và màn trình chiếu.
Member insight
Dùng thử vLLM-Omni theo từng bước
Bản public giúp bạn biết tool này có đáng mở tab không. Phần thành viên đi sâu hơn: nên thử hay theo dõi, chuẩn bị gì, làm từng bước thế nào để có output đầu tiên, và bẫy nào dễ làm mất thời gian.
- Practitioner guide: 5 bước thử nhanh, kèm chuẩn bị và kết quả kỳ vọng.
- Decision note: Nên thử ngay, theo dõi thêm, hay bỏ qua để khỏi mất công test sai lúc.
- Risk notes: Cạm bẫy triển khai, điều kiện kỹ thuật và lỗi dễ gặp khi thử.
- Nguồn kiểm chứng: 2 link cộng đồng/quốc tế để tự đánh giá trước khi đưa vào workflow.
- Bonus khuếch đại: Có góc nội dung cho creator/đội content nếu cần kéo người trong ngành về case này.